Machine Learning Types 중 가장 많이 쓰이는 것들을 그림으로 표현하면 아래와 같습니다.
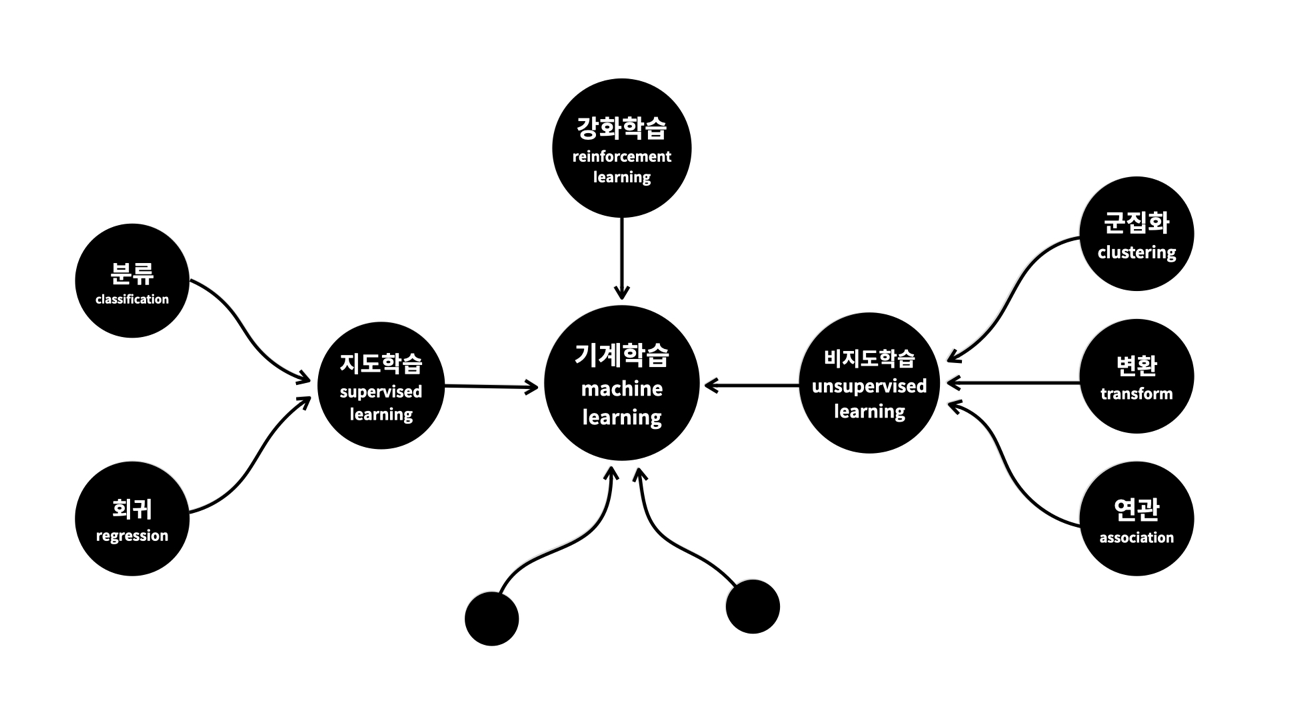
1. 지도 학습(Supervised Learning)의 ‘지도'는 기계를 가르친다(supervised)는 의미입니다. 문제집으로 학생을 가르치듯이 데이터로 컴퓨터를 학습시켜서 모델을 만드는 방식을 ‘지도 학습’이라고 합니다. 앞서 살펴본 손톱 감시 앱은 지도 학습을 이용한 것입니다. 지도 학습은 과거의 데이터로부터 학습해서 결과를 예측하는 데에 주로 사용됩니다.
지도 학습은 '역사'와 비슷합니다. 역사에는 과거에 있었던 사건이 원인과 결과로 기록되어 있습니다. 역사를 알면 어떤 사건이 일어났을 때,
그것의 결과로 어떤 일이 일어날지를 예측할 수 있게 됩니다. 마찬가지로, 지도 학습은 과거의 데이터로부터 학습해서 결과를 예측하는 데에 주로 사용됩니다. 예시로 ‘레모네이드 카페’ 예제를 불러오겠습니다.

일기예보를 보니 1월 8일에 온도가 25도라고 합니다. 우리가 궁금한 것은 1월 8일에는 레모네이드 몇 잔이 판매될지를 예측하는 것입니다.
그래야 레몬이 몇 개가 필요한지 알 수 있을 테니까요. 즉, 과거에 대한 학습을 통해서 미지의 데이터를 추측하고 싶은 것이죠. 이때 머신 러닝의 지도 학습이 이용될 수 있습니다. 머신러닝의 지도 학습을 이용하기 위해서는 우선 충분히 많은 데이터를 수집해야 합니다.
데이터는 독립변수와 종속변수로 이루어져 있어야 합니다. 이것을 지도학습으로 훈련시키면 컴퓨터는 'Model'을 만듭니다.
아마도 모델은 이렇게 생겼겠죠? ==> [ 온도 X 2 = 판매량 ]
일단 모델이 만들어지면, 모델을 사용하면 됩니다. 이 모델에 온도를 입력하면 판매량을 예측할 수 있습니다.
만약 내일의 온도가 25도라면 몇 잔이 판매될까요? 25도 X 2 = 50잔입니다. 즉, 머신러닝의 지도 학습을 이용하면 '온도 X2'라는 모델을 컴퓨터가 알아서 만들어주는 것입니다.
지도학습(Supervised Learning)은 크게 ‘회귀’와 ‘분류’로 나뉩니다. 회귀는 영어로 Regression이고, 분류는 Classification입니다.

위의 '레모네이드 카페'의 예제 같은 경우, 회귀는 예측하고 싶은 종속변수가 숫자일 때 보통 회귀라는 머신러닝의 방법을 사용합니다. 옆의 표는 Regression의 여러 사례들을 나타낸 것입니다.

앞의 예제에서 손톱을 깨무는 이미지들을 손톱이라는 이름으로 분류했던 것 기억나시나요? 그렇게 했더니 새로운 이미지가 나타났을 때 그것이 손톱인지, 정상인지를 분류할 수 있었습니다. 이것은 과거의 데이터를 통해서 배운다는 점에서 지도학습입니다. 그런데 결과가 회귀처럼 숫자가 아니라 손톱, 정상과 같은 이름입니다. 이럴때는분류라는 방법을 이용해야 합니다. 옆의 표는 Classification의 여러 사례들을 나타낸 것입니다.
위의 회귀와 분류를 정리해 본다면
"가지고 있는 데이터에 독립변수와 종속변수가 있고, 종속변수가 숫자일 때 회귀를 이용하면 됩니다."
"가지고 있는 데이터에 독립변수와 종속변수가 있고, 종속변수가 이름일 때 분류를 이용하면 됩니다."
cf)
산업에서는 숫자라는 다소 모호한 표현 대신에 ‘양적’이라는 말을 많이 사용합니다. 즉, 얼마나 큰지, 얼마나 많은지, 어느 정도인지를 의미하는 데이터라는 뜻에서 ‘양적(Quantitative)'이라고 합니다. 즉 종속변수가 양적 데이터라면 회귀를 사용하면 됩니다.
누가 여러분에게 양적 데이터라고 말했다면 숫자라고 알아들으면 됩니다. 또 산업에서는 ‘이름'이라는 표현 대신에 ‘범주(Categorical)'라는 말을 씁니다. 즉 종속변수가 범주형 데이터라면 분류를 사용하면 됩니다.
2. 비지도 학습(Unsupervised Learning)은 지도 학습에 포함되지 않는 방법들입니다. 여기에 속하는 도구들은 대체로 기계에게 데이터에 대한 통찰력을 부여하는 것이라고 이야기할 수 있을 것 같습니다. '통찰'의 사전적 의미는 '예리한 관찰력으로 사물을 꿰뚫어 봄'입니다.
즉, 누가 정답을 알려주지 않았는데도 무언가에 대한 관찰을 통해 새로운 의미나 관계를 밝혀내는 것이라고 할 수 있습니다. 데이터의 성격을 파악하거나 데이터를 잘 정리 정돈하는 것에 주로 사용됩니다.
3. 강화학습(reinforcement learning)은 학습을 통해서 능력을 향상한다는 점에서는 지도 학습이랑 비슷합니다. 차이점은 지도 학습이 정답을 알려주는 문제집이 있는 것이라면, 강화 학습은 어떻게 하는 것이 더 좋은 결과를 낼 수 있는지를 스스로 느끼면서 실력 향상을 위해서
노력하는 수련과 비슷합니다. 경험을 통해 “더 좋은 답”을 찾아가는 것입니다. 감이 안 오실 텐데 게임에 비유를 들어볼게요. 게임에는 룰이 있고, 룰에 따라 어떤 행동을 하면, 그 결과에 따라서 상이나 벌을 받습니다. 더 큰 상을 받기 위한 과정을 끝없이 반복하다 보면 그 게임의 고수가 됩니다. 이런 과정을 기계에게 시켜서 기계 스스로가 고수로 성장하도록 고안된 방법이 강화 학습이라고 할 수 있습니다.
+7.19
(위 3가지를 간단하게 표현한다면 아래와 같이 나타내 볼 수 있습니다.)

'Python > opentutorials(Machine Learning)' 카테고리의 다른 글
| 6. Finished Machine Learning (0) | 2021.07.20 |
|---|---|
| 5. Machine Learning Types (0) | 2021.07.19 |
| 3. Start Machine Learning (0) | 2021.07.17 |
| 2. About Machine Learning (0) | 2021.07.16 |
| 1. About Machine Learning (0) | 2021.07.15 |



