8.2 인덱스
: 책으로 예를 들었을 때 인덱스는 맨 뒤 찾아보기, 책의 내용은 데이터 파일에 해당한다고 볼 수 있다. 찾아보기를 통해 알 수 있는 페이지 번호는 데이터 파일에 저장된 레코드의 주소에 비유될 수 있다. 칼럼의 값과 해당 레코드가 저정된 주소를 키와 값의 쌍으로 삼아 인덱스를 만들어 두는 것이다. DBMS의 인덱스는 SortedList와 마찬가지로 저장되는 칼럼의 값을 이용해 항상 정렬된 상태를 유지한다. 데이터 파일은 ArrayList 같이 저장된 순서대로 별도의 정렬없이 그대로 저장한다. 결론적으로 DBMS에서 인덱스는 데이터의 저장 성능(INSERT, UPDATE, DELETE) 희생하고, 대신 데이터의 읽기 속도를 높이는 기능이다.
1. 인덱스를 역할별로 구분한다면 프라이머리 키, 세컨더리 키로 구분할 수 있다.
프라이머리 키
: 레코드를 대표하는 칼럼의 값으로 만들어진 인덱스를 의미한다. 이 칼럼은 테이블에서 해당 레코드를 식별할 수 있는 기준값이 되기 때문에 우리는 이를 식별자라고도 부른다. NULL과 중복을 허용하지 않는다.
세컨더리 인덱스
: 프라이머리 키를 제외한 나머지 모든 인덱스는 세컨더리 인덱스로 분류한다. 유니크 인덱스는 프라이머리 키와 성격이 비슷하고, 프라이머리 키를 대체해서 사용할 수도 있다고 해서 대체 키라고도 하는데, 별도로 분류하기도 하고 그냥 세컨더리 인덱스로 분류하기도 한다.
2. 데이터 저장 방식별로 구분하는 경우 대표적으로 B-Tree 인덱스와 Hash 인덱스로 구분할 수 있다.
B-Tree
: 가장 일반적으로 사용되는 인덱스 알고리즘으로, B-Tree 인덱스는 칼럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱하는 알고리즘이다. Mysql 서버에서는 위치 기반 검색을 지원하기 위한 R-Tree 인덱스 알고리즘도 있지만 이는 B-Tree의 응용이다.
Hash 인덱스
: 칼럼의 값으로 해시값을 계산해서 인덱싱하는 알고리즘으로 매우 빠른 검색을 지원한다. 하지만 값을 변형해 인덱싱하므로 값의 일부만 검색하거나 범위를 검색할 때는 Hash 인덱스를 사용할 수 없다. 주로 메모리 기반의 데이터베이스에서 많이 사용한다.
3. 데이터 중복 허용 여부로 분류하면 유니크 인덱스와 유니크 하지 않은 인덱스로 구분할 수 있다. (Unique or Non-Unique) 인덱스가 유니크한지 아닌지 단순히 같은 값이 1개만 존재하는지 1개 이상 존재할 수 있는지를 의미하지만, 실제 옵티마이저에게는 상당히 중요한 문제기 된다. 유니크 인덱스에 대해 동등 조건(Equal, =)으로 검색한다는 것은 항상 1건의 레코드만 더 찾지 않아도 된다는 것을 옵티마이저에게 알려주는 효과를 낸다.
8.3 B-Tree 인덱스
: 가장 범용적인 목적으로 사용되는 알고리즘이다. 여러 변형 형태가 있으며 DBMS에서는 B+-Tree, B*-Tree가 사용된다. 칼럼의 원래 값을 변경하지 않고, 인덱스 구조체 내에서는 항상 정렬된 상태로 유지한다.
1. 구조 및 특성
: B-Tree 인덱스를 제대로 사용하려면 기본적인 구조를 알아야 한다. 최상위에 "루트 노드"가 존재하고, 그 하위에 자식 노드가 붙어 있는 형태다. 데이터베이스에서 인덱스와 실제 데이터가 저장된 데이터는 따로 관리되는데, 인덱스의 리프 노드는 항상 실제 데이터 레코드를 찾아가기 위한 주솟값을 가지고 있다. 아래는 각 노드와 데이터 파일의 관계를 표현한 것이다.

인덱스의 키 값은 모두 정렬돼 있지만, 데이터 파일의 레코드는 정렬돼 있지 않다. 대부분 RDBMS 데이터 파일에서 레코드는 임의의 순서로 저장된다. 하지만 InnoDB 테이블에서 레코드는 클러스터되어 디스크에 저장되므로 기본적으로 프라이머리 키 순서로 정렬되어 저장된다. Default로 클러스터링 테이블이 생성되고, 클러스터링이란 비슷한 값을 최대한 모아 저장하는 방식을 얘기한다.


위는 MyISAM 테이블의 인덱스와 파일의 데이터 관계를 보여주는데, "레코드 주소"는 MyISAM 테이블의 생성 옵션에 따라 레코드가 INSERT된 순번이거나 데이터 내의 위치다. 그리고 InnoDB 테이블의 인덱스 데이터 파일의 관계도 있는데, InnoDB 스토리지 엔진을 사용하는 테이블에서는 프라이머리 키가 ROWID의 역할을 한다.
두 스토리지 엔진의 인덱스에서 가장 큰 차이점은 세컨더리 인덱스를 통해 데이터 파일의 레코드를 찾아가는 방법에 있다. MyISAM 테이블은 세컨더리 인덱스가 물리적인 주소를 가지는 반면 InnoDB 테이블은 프라이머리 키를 주소처럼 사용하기 때문에 논리적인 주소를 가진다고 볼 수 있다.
그래서 InnoDB 테이블에서 인덱스를 통해 레코드를 읽을 때는 데이터 파일을 바로 찾아가지 못한다. 인덱스에 저장돼 있는 프라이머리 키 값을 이용해 프라이머리 키 인덱스를 한 번 더 검색한 후, 프라이머리 키 인덱스의 리프 페이지에 저장돼 있는 레코드를 읽는다. 즉, InnoDB 스토리지 엔진에서는 모든 세컨더리 인덱스 검색에서 데이터 레코드를 읽기 위해서는 반드시 프라이머리 키를 저장하고 있는 B-Tree를 다시 한번 검색해야 한다.
2. B-Tree 인덱스 키 추가 및 삭제
: 새로운 키 값이 B-Tree에 저장될 때 테이블의 스토리지 엔진에 따라 새로운 키 값이 즉시 인덱스에 저장될 수도 있고, 그렇지 않을 수도 있다. B-Tree에 저장될 때 적절한 위치를 검색해야 하는데, 결정되면 레코드의 키값 + 레코드의 주소 정보를 B-Tree 리프 노드에 저장한다. 리프 노드가 꽉차서 저장할 수 없다면 리프 노드가 분리(Split)돼야 하는데, 상위 브랜치 노드까지 처리의 범위가 넒어진다. 때문에 B-Tree는 상대적으로 쓰기 작업에 비용이 많이 드는 것으로 알려졌다.
인덱스 추가로 인해 INSERT, UPDATE 문장의 영향은 테이블의 칼럼 수, 크기, 특성을 확인해야 한다. 대락 계산 방법은 테이블에 레코드 추가 비용이 1이라고 가정하면, 추가 작업 비용은 1.5정도로 예측하는 것이다. 일반적으로 테이블에 인덱스가 3개 있다면, 인덱스가 하나도 없는 경우는 작업 비용이 1이고, 3개인 경우에는 5.5정도의 비용(1.5 * 3 + 1) 정도로 예측한다. 중요한 것은 비용의 대부분이 메모리와 CPU에서 처리하는 시간이 아니라 디스크부터 인덱스 페이지를 읽고 쓰기를 해야 해서 걸리는 시간이라는 점이다.
MyISAM, MEMORY 스토리지 엔진을 사용하는 테이블에서는 INSERT 문장이 실행되면 즉시 새로운 키 값을 B-Tree 인덱스에 변경한다. InnoDB 스토리지 엔진은 더 지능적으로 인덱스 키 추가 작업을 지연시켜 나중에 처리(체인지 버퍼 참고)할 수 있다. 하지만 프라이머리 키나 유니크 인덱스의 경우 중복 체크가 필요하기 때문에 즉시 B-Tree에 추가하거나 삭제한다.
INSERT, UPDATE, DELETE 작업 시 인덱스 관리에 따르는 추가 비용을 감당하면서 인덱스를 구축하는 이유는 빠른 검색을 위해서다. 인덱스를 검색하는 작업은 B-Tree 루트 노드부터 시작해 리프 노드까지 이동하며 비교 작업을 수행하는데, 이를 "트리 탐색" 이라고 한다. B-Tree 인덱스를 이용한 검색은 100% 일치 또는 값의 앞부분만 일치하는 경우에 사용할 수 있다. InnoDB 테이블에서 지원하는 레코드 잠금이나 넥스트 키락이 검색을 수행한 인덱스를 잠근 후 테이블의 레코드를 잠그는 방식으로 구현돼 있다. 따라서 UPDATE, DELETE 문장이 실행될 때 적절히 사용할 수 있는 인덱스가 없으면 불필요하게 많은 레코드를 잠근다.
8.3.3 B-Tree 인덱스 사용에 영향을 미치는 요소
1. 인덱스 키 값의 크기
: InnoDB 스토리지 엔진은 디스크에 데이터를 저장하는 가장 기본 단위를 페이지 또는 블록이라고 하고, 디스크의 모든 읽기 및 쓰기 작업의 최소 단위가 된다. 페이지는 InnoDB 버퍼 풀에서 데이터를 버퍼링하는 기본 단위이기도 하다. 인덱스도 결국 페이지 단위로 관리되며, 루트, 브랜치, 리프 노드를 구분한 기준이 바로 페이지 단위다.

Mysql의 B-Tree는 인덱스의 페이지 크기와 키 값의 크기에 따라 달라진다. Mysql5.7 이상 InnoDB 엔진의 페이지 크기 기본값은 16KB이다. 인덱스의 키가 16바이트라고 가정하고, 자식 노드 주소라는 것은 여러가지 복합적인 정보가 담긴 영역이고, 페이지의 종류별로 대략 6~12 바이트까지 다양한 크기의 값을 가질 수 있어 여기서는 편의상 12바이트로 가정한다. 이처럼 가정했을 경우, 인덱스 페이지에 몇 개의 키를 저장할 수 있을까? 이는 최종적으로 자식 노드를 16 * 1024 / (16 + 12) = 585개 저장할 수 있다.
만약 인덱스 키 값이 커지면 (32 + 12) 이고, 372개 저장할 수 있다. 인덱스를 구성하는 키 값의 크기가 커지면 디스크로부터 읽어야 하는 횟수가 늘어나고, 그만큼 느려진다는 것을 의미한다. 또한 인덱스의 키 값의 길이가 길어지는 것은 전체적인 인덱스의 크기가 커지는 것이지만, 인덱스를 캐시해두는 InnoDB 버퍼 풀, MyISAM 키 캐시 영역은 크기가 제한적이라 하나의 레코드를 위한 인덱스 크기가 커지면 커질수록 메모리에 캐시해 둘 수 있는 레코드 수는 줄어든다. 자연히 메모리의 효율이 떨어지게 될 것이다.
2. B-Tree 깊이
: 이는 직접 제어는 불가하고, 예제로 살펴보겠다. 인덱스의 B-Tree 깊이가 3인 경우 최대 몇 개의 키 값을 가지는지 보자. 키 값이 16 바이트 경우에 최대 2억 (585 * 585 * 585) 정도 키 값을 담을 수 있지만, 키 값이 32바이트로 늘어나면 5천만(372 * 372 * 372)개로 줄어든다. B-Tree 깊이는 Mysql에서 에서 검색할 때 몇 번이나 랜덤하게 디스크를 읽어야 하는지와 직결되는 문제다. 결론적으로 인덱스 키 값의 크기가 커지면 커질수록 하나의 인덱스 페이지가 담을 수 있는 인덱스 키 값의 개수가 적어지고, 때문에 같은 레코드 건수라 하더라도 B-Tree 깊이가 깊어져 디스크 읽기가 더 많이 필요하다. 인덱스 키 값의 크기는 가능하면 작게 만드는 것이 좋다.
3. 선택도(기수성)
: 인덱스에서 선택도 or 기수성은 거의 같은 의미로 사용되며, 모든 인덱스 키 값 가운데 유니크한 값의 수를 의미한다. 전체 인덱스 키 값은 100개인데, 그중에서 유니크한 값의 수는 10개라면 기수성은 10이다. 인덱스는 선택도가 높을수록 검색 대상이 줄기 때문에 빠르게 처리된다.
4. 읽어야 하는 레코드의 건수
: 인덱스를 이용한 읽기의 손익 분기점이 얼마인지 판단할 필요가 있는데, 일반적인 DBMS 옵티마이저에서는 인덱스를 통해 레코드 1건을 읽는 것이 테이블에서 직접 레코드 1건을 읽는 것보다 4~5배 정도 비용이 더 많이 드는 작업인 것으로 예측한다. 즉 인덱스를 통해 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25% 넘어서면 인덱스를 이용하지 않고, 모두 직접 읽어 필요한 레코드만 가려내는 것이 효율적이다.
전체 100만 건의 레코드 가운데 50만 건을 읽어야 하는 작업은 인덱스의 손익 분기점인 20~25%보다 훨씬 크기 때문에 옵티마이저는 인덱스를 이용하지 않고 처음부터 끝까지 읽을 것이다.
8.3.4 B-Tree 인덱스를 통한 데이터 읽기
1. 인덱스 레인지 스캔
: 인덱스의 접근 방법 가운데 가장 대표적인 접근 방식으로, 아래의 2,3번 보다 빠른 방법이다. 인덱스를 통해 한 건만 읽는 경우와 그 이상을 읽는 경우를 각각 다른 이름으로 구분하지만, 이번 절에서는 모두 묶어서 "인덱스 레인지 스캔"이라고 표현했다. 만약 아래의 쿼리문 실행시
mysql > SELECT * FROM employees WHERE first_name BETWEEN "Ebbe" AND "Gad";

검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식이다. 루트 노드부터 리프 노드까지 찾아 들어가야만 비로소 필요한 레코드의 시작 지점을 찾을 수 있다. 리프 노드의 끝까지 읽으면 리프 노드 간의 링크를 이용해 다음 링크를 이용하고, 멈춰야 할 위치에 도착하면 지금까지 읽은 레코드를 사용자에게 반환하고 쿼리를 끝낸다.

B-Tree 인덱스에서 루트와 브랜치 노드를 이용한 스캔 시작 위치를 검색하고, 그 지점부터 필요한 방향으로 인덱스를 읽어 나가는 것을 위에서 볼 수 있다. 어떤 방식으로 스캔하든, 해당 인덱스를 구성하는 칼럼의 정순, 역순 중 하나로 정렬되어 레코드를 가져오며 인덱스 자체의 정렬 특성 때문에 그러하다.
중요한 것은 인덱스 리프 노드에서 검색 조건에 일치하는 건들은 데이터 파일에서 레코드를 읽어오는 과정이 필요하다는 것이다. 리프 노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어오는데, 레코드 한 건 단위로 랜덤 I/O가 일어난다. 그래서 인덱스를 통해 읽어야 할 데이터 레코드가 20~25% 넘으면 인덱스를 통한 읽기보다 테이블의 데이터를 직접 읽는 것이 더 효율적인 처리 방식이 된다.
1) 인덱스에서 조건을 만족하는 값이 저장된 위치를 찾는다. [ "인덱스 탐색" 과정이라고 한다 ]
2) 1번에서 탐색된 위치부터 필요한 만큼 인덱스를 차례대로 쭉 읽는다. [ "인덱스 스캔" 이라고 한다 ]
3) 2번에서 읽어 들인 인덱스 키와 레코드 주소를 이용해 레코드가 저장된 페이지를 가져오고, 최종 레코드를 읽어온다.
쿼리가 필요로 하는 데이터에 따라 3)은 필요하지 않을 수 있는데 ,이를 커버링 인덱스라고 한다. 커버링 인덱스로 처리되는 쿼리는 디스크의 레코드를 읽지 않아도 되기 때문에 랜덤 읽기가 상당히 줄고 성능이 빨라진다.
2. 인덱스 풀 스캔
: 인덱스 레인지 스캔과 마찬가지로 인덱스를 사용하면서 처음부터 끝까지 모두 읽는 방식이다. 쿼리의 조건절에 사용된 칼럼이 인덱스의 첫 번째 칼럼이 아닌 경우 인덱스 풀 스캔 방식이 적용된다. 일반적으로 인덱스의 크기는 테이블의 크기보다 작으므로 직접 테이블을 처음부터 끝까지 읽는 것보다는 인덱스만 읽는 것이 효율적이다. 쿼리가 인덱스에 명시된 칼럼만으로 조건을 처리할 수 있는 경우 이렇게 사용된다. 인덱스뿐만 아니라 데이터 레코드까지 모두 읽어야 한다면 다른 방식으로 처리된다.

먼저 인덱스 리프 노드의 제일 앞 또는 뒤로 이동해서, 인덱스의 리프 노드를 연결하는 LinkedList를 따라서 처음부터 끝까지 스캔하는 방식을 인덱스 풀 스캔이라고 한다. 인덱스에 포함된 칼럼만으로 쿼리를 처리하는 경우 테이블의 레코드를 읽을 필요가 없기 때문에 이 방식을 사용한다. 레인지 스캔보다는 빠르지 않지만 테이블 풀 스캔보다는 효율적이다.
3. 루스 인덱스 스캔
: 위 인덱스 풀 스캔, 인덱스 레인지 스캔을 타이트(Tight) 인덱스 스캔으로 분류한다면, 이는 느슨하게 또는 듬성듬성하게 인덱스를 읽는 것을 의미한다. 중간에 필요하지 않은 인덱스 키 값은 무시(SKIP)하고 당므으로 넘어가는 형태로 처리된다. 일반적으로 GROUP BY, 집합 함수 가운데 MAX(), MIN() 함수에 대해 최적화를 할 때 사용된다.

4. 인덱스 스킵 스캔
: 이 인덱스를 사용하려면 WHERE 조건절에 gender 칼럼에 대한 비교 조건이 필수다.
>mysql ALTER TABLE employees
ADD INDEX ix_gender_birthdate (gender, birth_date)
// 인덱스를 사용하지 못하는 쿼리
mysql> SELECT * FROM employees WHERE birth_date>= '1965-02-01';
// 인덱스를 사용할 수 있는 쿼리
mysql> SELECT * FROM employees WHERE gender = 'M' AND birth_date>= '1965-02-01';
위에서 gender, birth_date 칼럼의 조건을 가진 2번째 쿼리는 인덱스를 효율적으로 사용할 수 있지만, gender 칼럼에 비교 조건이 없는 1번째는 인덱스를 사용할 수 없다. Mysql8.0 버전부터 옵티마이저가 gender 칼럼을 건너뛰어서 birth_date 컬럼만으로 인덱스 검색이 가능한 인덱스 스킵 스캔과 비슷한 최적화를 수행하는 루스 인덱스 스캔이라는 기능이 있었지만 루스 인덱스 스캔은 GROUP BY 작업에만 처리되도록 적용할 수 있었다. 하지만 8.0 버전에 도입된 인덱스 스킵 스캔은 WHERE 조건절의 검색을 위해 사용가능하도록 하였다.
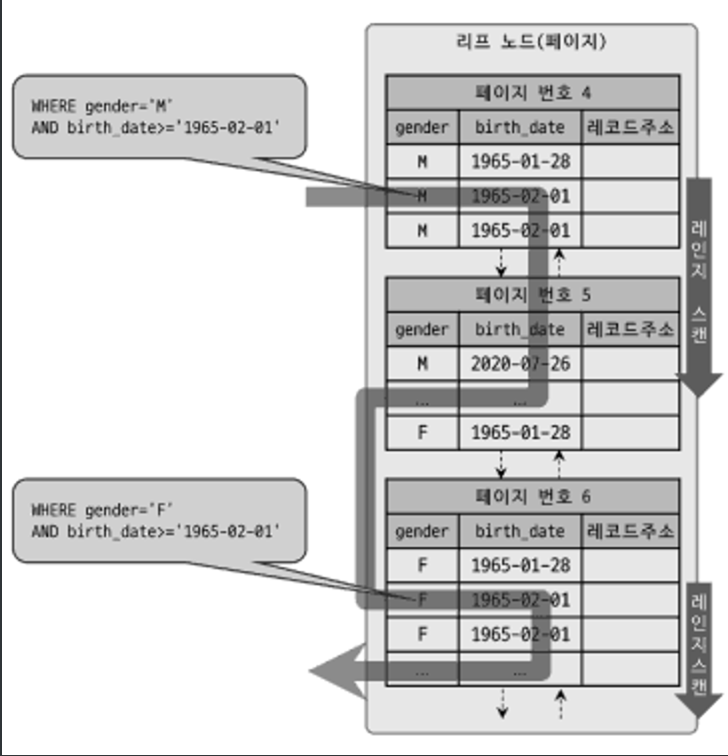
Mysql 옵티마이저는 우선 gender 칼럼에서 유니크한 값을 모두 조회해서 주어진 쿼리에 gender 칼럼의 조건을 추가해서 쿼리를 다시 실행하는 형태로 처리한다. 위를 예로 gender 칼럼에 대해 가능한 값 2개를 구한 다음, 내부적으로 2개의 쿼리를 실행하는 것과 비슷 형태의 최적화를 실행하게 된다.
단점으로는 WHERE 조건절에 조건이 없는 인덱스의 선행 칼럼의 유니크한 값의 개수가 적어야 하고, 쿼리가 인덱스에 존재하는 컬럼만으로 처리 가능해야 한다.
5. 다중 칼럼 인덱스
: 위는 인덱스들이 모두 1개의 칼럼만 포함된 인덱스였다. 실제 서비스용 데이터베이스에서는 2개 이상의 칼럼을 가진 인덱스가 더 많이 사용된다. 2개 이상의 컬럼으로 구성된 인덱스를 다중 칼럼 인덱스라고 한다.

실제로 데이터 건수가 작은 경우 브랜치 노드가 없는 경우가 있을 수 있다. 하지만 루트, 리프 노드는 항상 존재하고, 위는 다중 칼럼 인덱스 일 때 각 인덱스를 구성하는 칼럼의 값이 어떻게 정렬되어 저장되는지 보여준다. 다중 칼럼 인덱스는 인덱스 내에서 칼럼의 위치가 상당히 중요하며, 신중히 결정해야 한다.
6. B-Tree 인덱스의 정렬 및 스캔 방향
: 인덱스를 생성할 때 설정한 정렬 규칙에 따라 인덱스의 키 값은 항상 오름, 내림차순으로 정렬된다. 인덱스를 어느 방향으로 읽을지는 쿼리에 따라 옵티마이저가 실시간으로 만들어내는 실행 계획에 따라 결정된다. Mysql 8.0 버전에서 아래와 같은 정렬 순서를 혼합한 인덱스도 생성할 수 있게 됐다.

first_name 칼럼에 대한 인덱스가 포함된 employees 테이블에 대해 아래 쿼리를 보자.
mysql> CREATE INDEX ix_teamname_userscore ON employees (team_name ASC, user_score DESC);
인덱스 생성 시점에 오름차순 또는 내림차순으로 정렬이 결정되지만 쿼리가 그 인덱스를 사용하는 시점에 인덱스를 읽는 방향에 따라 오름차순 또는 내림차순 정렬 효과를 얻을 수 있다. 오름차순으로 생성된 인덱스를 정순으로 읽으면 출력되는 결과 레코드는 자동으로 오름차순 정렬된 결과가 되고, 역순으로 읽으면 결과는 내림차순으로 정렬된 상태가 되는 것이다.
하나의 인덱스를 정순, 역순으로 읽느냐에 차이가 발생하는 것을 이해하기 어려울 수 있다. Mysql 서버의 InnoDB 스토리지 엔진에서 정순, 역순 스캔은 페이지간의 양방향 연결 고리(Double Linked List) 통해 전진, 후진 하느냐의 차이만 있지만 실제 내부적으로 InnoDB에서 인덱스 역순 스캔이 인덱스 정순 스캔에 비해 느릴 수 밖에 없는 다음의 2가지 이유가 있다. 결국 쿼리에서 자주 사용되는 정렬 순서대로 인덱스를 생성하는 것이 잠금 병목 현상을 완화하는 데 도움이 될 것이다.
1. 페이지 잠금이 인덱스 정순 스캔에 적합한 구조
2. 페이지 내에서 인덱스 레코드가 단방향으로만 연결된 구조
7. B-Tree 인덱스의 가용성과 효율성
: 쿼리의 Where 조건이나 GROUP BY, ORDER BY 절이 어떤 경우에 인덱스를 사용할 수 있고, 어떤 방식으로 사용할 수 있는지 식별할 수 있어야 한다.
1) 비교 조건의 종류와 효율성
: 다중 칼럼 인덱스에서 각 칼럼의 순서와 칼럼에 사용된 조건이 ("=", ">", "<") 각각에 따라 인덱스 칼럼의 활용 형태가 달라진다.
mysql> SELECT * FROM dept_emp WHERE dept_no = 'd002' AND emp_no >= 10114;
여기서 칼럼의 순서만 다른 2케이스 인덱스를 가정하자. (1) INDEX (dept_no, emp_no) (2) INDEX (emp_no, dept_no)
이처럼 인덱스를 통해 읽은 레코드가 나머지 조건에 맞는지 비교하면서 취사선택하는 작업을 '필터링'이라고도 한다. 위 케이스는 다른 비교 횟수를 가져오는데, 이유는 '다중 칼럼 인덱스' 정렬 방식 때문이다.(인덱스의 N번째 키 값은 N-1번째 키값에 대해 다시 정렬됨)
(1)과 같이 두 조건 작업 범위를 결정하는 조건을 '작업 범위 결정 조건', (2)과 같이 단순히 거름종이 역할만 하는 조건을 '필터링 조건', '체크 조건'이라고 한다. 쿼리 처리 성능에 영향이 있다.
2) 인덱스의 가용성
: B-Tree 인덱스 특징은 왼쪽 값에 기준해서 오른쪽 값이 정렬돼 있다는 것이다. 여기서 왼쪽이란 하나의 칼럼 뿐만 아니라 다중 컬럼 인덱스의 칼럼에 대해서도 적용된다. (1) INDEX (first_name) (2) INDEX (dept_no, emp_no) 가정하자. 아래 그림에서 인덱스 키 값의 정렬만 표현하지만 사실 인덱스 키 값의 이런 정렬 특성은 빠른 검색의 전제 조건이다. 하나의 칼럼으로 검색해도 값의 왼쪽 부분이 없으면 인덱스 레인지 스캔 방식의 검색이 불가하다. 또한 다중 컬럼 인덱스에서도 왼쪽 컬럼의 값을 모르면 인덱스 레인지 스캔을 사용할 수 없다.

[ 1 ] mysql> SELECT * FROM employees WHERE first_name LIKE '%mer';
위 쿼리는 인덱스 레인지 스캔 방향으로 인덱스를 이용할 수 없다. 왼쪽부터 한 글자씩 비교하며 일치하는 레코드를 찾아야 하는데, 고정되어 있지 않기 때문이다. 그래서 왼쪽 정렬 기반의 인덱스인 B-tree에서 인덱스의 효과를 얻을 수 없다.
[ 2 ] mysql> SELECT * FROM dept_emp WHERE emp_no >= 10144;
위 쿼리는 (2) 처럼 인덱스 칼럼 순서대로 생성돼 있다먄, 인덱스의 선행 칼럼인 dept_no 조건없이 emp_no 값으로만 검색하면 인덱스를 효율적으로 사용할 수 없다. 다중 칼럼으로 구성된 (2) 인덱스이기 때문에 dept_no 칼럼에 대해 먼저 정렬하고, 다시 emp_no 칼럼값으로 정렬되기 때문이다. 이는 WHERE 뿐만 아니라 GROUP BY, ORDER BY에 대해서도 똑같이 적용된다.
다른 DBMS에서 NULL 값이 인덱스에 저장되지 않지만, Mysql에서는 인덱스에 저장된다. 작업 범위 결정 조건으로 사용 가능하다.
8.4 R-Tree 인덱스
: 공간 인덱스는 B-Tree 인덱스 알고리즘을 이용해 2차원 데이터를 인덱싱하고 검색하는 목적의 인덱스다. 내부 메커니즘은 비슷하며, B-Tree 인덱스를 구성하는 칼럼의 값이 1차원의 스칼라 값인 반면, R-Tree 인덱스는 2차원의 공간 개념 값이다. 예로 위치 기반의 서비스를 구현하는 방법은 여러가지가 있겠지만, Mysql 공간 확장(Spatial Extension) 이용하면 간단하게 이러한 기능을 구현할 수 있다.
1. 공간 데이터를 저장할 수 있는 데이터 타입
2. 공간 데이터의 검색을 위한 공간 인덱스(R-Tree 알고리즘)
3. 공간 데이터의 연산 함수(거리 또는 포함 관계의 처리)
1) 구조 및 특성
: Mysql은 공간 정보의 저장 및 검색을 위해 여러 기하학적 도형 정보를 관리할 수 있는 데이터 타입을 제공한다. (POINT, LINE, POLYGON, 나머지 3개의 슈파타입)공간 정보의 특성을 이해하기 위해 'MBR'(Minimum Bounding Rectangle) 이라는 개념을 알아야 한다. 해당 도형을 감싸는 최소 크기의 사각형을 의미하며, 이 사각형들의 포함 관계를 B-Tree 형태로 구현한 인덱스가 R-Tree 인덱스다.
MBR의 구성을 알아보자. 도형들의 MBR을 3개 레벨로 나눠서 그려본 것이다.

- 최상위 레벨 : R1, R2
- 차상위 레벨 : R3, R4, R5, R6
- 최하위 레벨 : R7 ~ R14
최하위 레벨의 MBR은 각 도형 데이터의 MBR을 의미한다. 차상위 레벨의 MBR은 중간 크기의 MBR이다. 최상위 MBR은 R-Tree 루트 노드에 저장되는 정보이며, 차상위 그룹 MBR은 R-Tree의 브랜치 노드가 된다. 마지막으로 각 도형의 객체는 리프 노드에 저장되므로 아래와 같이 표현이 가능하다.

2) R-Tree 인덱스 용도
: R-Tree는 MBR 정보를 이용해 B-Tree 형태로 인덱스를 구축하고, 공간 인덱스라고도 한다. 일반적으로는 WGs84(GPS) 기준의 위도, 경도 좌표 저장에 주로 사용된다. 도형의 포함 관계를 이용해서 만들어진 인덱스이며, ST_Contains() or ST_Within() 과 같은 포함 관계를 비교하는 함수로 검색을 수행하는 경우에만 인덱스를 이용할 수 있다.

'P'가 기준점이다. 기준점으로부터 반경 거리 5km 이내의 점들을 검색하려면 우선 사각 점선의 상자에 포함되는 점들을 검색하면 된다. 여기서 위에 사용하는 연산은 사각형 박스와 같은 다각형(Polygon)으로만 연산할 수 있으므로 반경 5km를 그리는 원을 포함하는 최소 사각형(MBR)으로 포함 관계 비교를 수행한 것이다. 예로 점 'P6'은 원을 벗어나 최소 사각형 내 포함되어 있다.(위 연산시 포함 결과 해당)
* SSD가 HDD 보다 빠르다.
* 랜덤 I/O : HDD 플레터를 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동 시킨 다음 데이터를 읽는 것 (순차 I/O 더 빠름)
'독서 > RealMySQL 8.0' 카테고리의 다른 글
| 7. 데이터 암호화 (0) | 2024.01.14 |
|---|---|
| 6. 데이터 압축 (0) | 2024.01.13 |
| 5. 트랜잭션 (2) | 2024.01.07 |
| 4.3 아키텍처 (하) (2) | 2024.01.07 |
| 4.2 아키텍처 (중) (1) | 2024.01.04 |



